

Tensor Cores et DLSS, où en sommes nous six mois après la sortie de RTX ?
Nvidia a introduit ces deux nouvelles technologies avec l’architecture Turing. En effet, les Tensor Cores et DLSS (Deep Learning Super Sampling) ont été dévoilées au grand public et intégrées récemment aux GeForce RTX. Alors, la communauté s’est lancée dans des campagnes de tests aussi nombreuses que variées. Des centaines d’heures de tests et d’analyse d’images, très subjectives parfois, pour au final conclure de gains certains en vitesse mais pas forcément en qualité. Rien de très probant, d’autant que les mises à jour des drivers Nvidia sont pas si fréquentes et si efficientes qu’annoncées, et alors que l’adhésion du Ray Tracing temps réel par les studios est encore timide. Mais avant de commenter les résultats, les Tensor Cores et DLSS, « comment ça marche ? ».
Les Tensor Cores, selon Nvidia
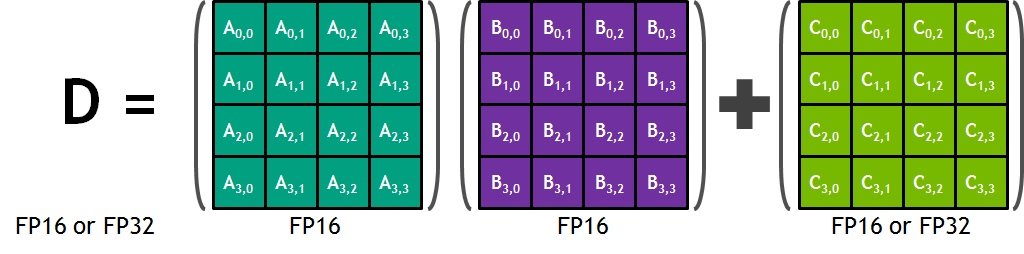
En 2017, Nvidia lançait les Tensor Cores avec ses solutions de GPU pour les data centers, les Volta V100. Les Tensor Cores sont des accélérateurs matériels utiles à faire des multiplications/additions de matrices, sources de toutes les convolutions et opérations sur ces objets mathématiques. En application graphique, les développeurs peuvent faire appel à des librairies CUDA C++ de fonctions adaptées et optimisées pour ces types de calculs. Cerise sur le gâteau, les Tensor Cores sont capables, entre autres, de réaliser des opérations en virgule flottante en pleine précision (FP32). En effet, la multiplication en entrée se fera en demi-précision (FP16) pour un résultat en accumulation en pleine précision (FP32). C’est ce que Nvidia nomme la précision mixte. Ainsi, les Tensor Cores de l’architecture Volta V100 produisent 12 fois plus d’opérations que l’architecture Pascal P100.
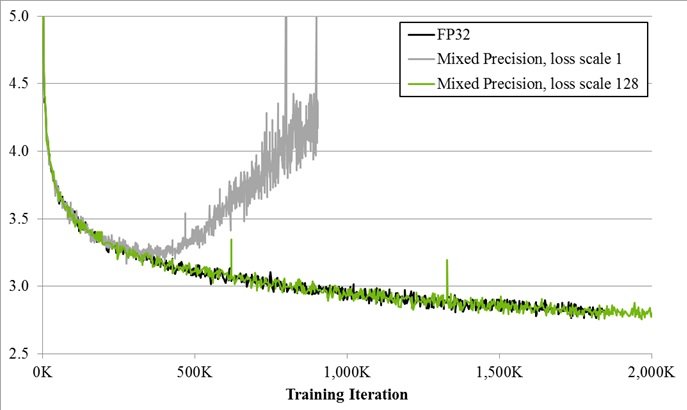
D’ailleurs, les ingénieurs de Nvidia ont produit des analyses sur la convergence de leur modèle en précision mixte. Les comparaisons avec le modèle en pleine précision sont plutôt bonnes, et ce à moindre coût. En effet, une multiplication de plus par cycle grâce au facteur de mise à l’échelle (loss scale à 128) suffit à apporter un apprentissage sensiblement identique (cf. graphe ci-dessous) qu’à celui en pleine précision. Là où l’apprentissage en précision mixte sans facteur de mise à l’échelle (loss scale 1) lui diverge autour 500 000 itérations.
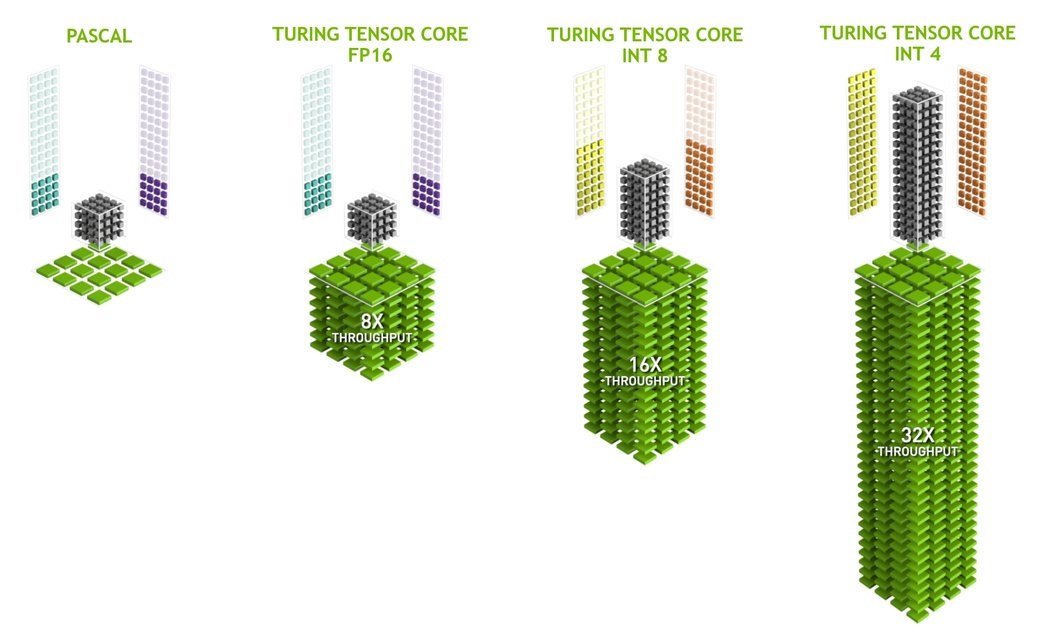
À savoir, la pleine précision (FP32) est un des algorithmes d’apprentissage de base que les réseaux de neurones utilisent. D’autres, comme INT4 et INT8, permettent aussi de gros calculs arithmétiques sur les chiffres entiers. Notamment grâce aux Tensor Cores, le nouveau mode de précision INT8 fonctionne deux fois plus vite, soit 2048 opérations sur entiers par cycle d’horloge.
Ce faisant, nous trouvons alors la transition naturelle vers le DLSS.
Et le DLSS fut
La technologie « Deep Learning Super Sampling » (DLSS) utilise la puissance de l’intelligence artificielle pour augmenter la fréquence d’images dans des jeux avec des charges de travail intensives en graphisme. D’après Nvidia et grâce au DLSS, les joueurs peuvent utiliser des résolutions et des paramètres plus élevés tout en conservant des fréquences d’affichage d’images. Néanmoins dans ses communications grand public et même spécialisées, Nvidia a tendance à rester assez superficiel et flou quant à la description du fonctionnement de DLSS. Encore récemment même lorsque Andrew Edelsten, directeur technique du Deep Learning chez Nvidia, tente de rassurer, nous restons sur notre faim. Pourquoi ces circonvolutions ? Est-ce que l’œil vert de Sauron aurait une nouvelle fois quelque chose à cacher ?
Quoiqu’il en soit, Nvidia pousse cette nouvelle solution DLSS à aller plus loin que TAA (« Anti-Aaliasing Temporel », une technique permettant de lisser le balayage et le scintillement vus en mouvement tout en jouant à un jeu) présente dans l’ancienne architecture Pascal. DLSS permet à Nvidia d’assurer de meilleures performances que le TAA pour des résolution élevée, de type QHD et 4K, et aussi apporter simultanément une meilleure qualité d’image. En effet, le principe de DLSS est d’offrir des gains sur des framerates peu élevés (autour de 60 images par seconde), ou dans des grandes résolutions. Tout cela varie énormément selon le jeu et le moteur de jeu. A contrario pour les jeux à fort taux d’images par secondes, DLSS sera désactivé.
Dans la vraie vie
En test et sur la base des quelques jeux sortis jusqu’à lors (Final Fantasy XV, Metro Exodus et Battlefield V), le DLSS produit quelques menus gains qualitatifs par rapport au TAA. Le 4K est la résolution de prédilection du DLSS. Chose assez surprenante, certes les résultats en débit d’image sont meilleurs, mais la qualité ne semble pas être au rendez-vous. Un détail intéressant à noter, les toutes premières images d’une scène sont de moins bonne qualité qu’après une quarantaine d’images. C’est ce que constate nos confrères de WCCFTech. Est-ce là le résultat de l’apprentissage et des calculs réalisés par les Tensor Cores ?

Le but de Nvidia est de s’appuyer sur les avantages des réseaux de neurones afin d’améliorer l’expérience de jeu. Les réseaux de neurones sont en mathématique des algorithmes d’intelligence artificielle. Ils permettent à un système de prendre rapidement des décisions sur la base de son apprentissage. Plus le nombre d’échantillon est grand, meilleures seront les prises de décision, ou meilleure sera la qualité du rendu. L’utilisation de DLSS est alors justifiée sur des résolutions de type 4K (nombre de pixels très élevé).
Conclusion et questionnements
De ces constats, que pouvons-nous conclure ? Plus l’utilisateur va jouer, meilleure sera son expérience de jeu ? Sera-ce aussi évident ? Nvidia et les studios de développement de jeu vidéo travaillent là-dessus depuis plusieurs mois déjà. Nvidia accumule l’expérience et les heures de jeux pour l’apprentissage et le développement des inférences. Pour l’heure, l’apprentissage s’effectue sur les supercalculateurs de Nvidia et les inférences sont et seront injectées via GeForce Experience. Aussi, les bases de données continuent à être affinées en central. Même si des inférences seront toujours traitées en local par l’utilisateur final.
Mais comment tout cela va s’organiser ? Les phases d’apprentissage sont indépendantes et spécifiques à tel ou tel jeu vidéo. Ici, toutes les suppositions sont bonnes à énoncer, même les plus folles se transformant alors en inquiétudes. Outre Geforce Experience, est-ce que Nvidia va créer un cloud ? Sinon, quelle quantité de donnée sera transférée et archivée en local ? Seulement les inférences, c’est-à-dire le résultat de l’apprentissage ? Nous pouvons alors et aussi nous demander, à quoi va servir la ressource matérielle locale (les Tensor Cores) une fois que l’apprentissage sera terminé ? Nvidia est resté dans ce qu’il y a de plus simple de ce côté-là. Les Tensor Cores sont utilisables pas seulement pour les routines d’apprentissages.






{kind=link}