

La solution miracle au problème de stockage de données ?
Vous l’ignoriez peut-être, mais c’est effectivement un problème. La production de données dépasse nos capacités actuelles de stockage. C’est donc dans le but de trouver une solution à ce problème que les chercheurs expérimentent des méthodes de stockage alternatives telles que l’ADN.
Il se trouve que stocker des données sous forme d’ADN n’a rien de nouveau. Il s’agit là de quelque chose que l’on sait faire depuis plusieurs années. Le problème résidait dans la manière de faire. En effet jusqu’à maintenant, la tâche s’effectuait à la main. Mais c’est là que Microsoft et l’université de Washington entrent en jeu. La firme américaine nous révèle avoir réussi à automatiser le processus !


La première étape c’est l’encodage. Un programme fait correspondre les données binaires aux bases A, T, C et G de l’ADN (plus de détails sur l’ADN en fin d’article). Ensuite, ces informations transitent vers une machine qui synthétise l’ADN. L’ADN, lors de sa synthèse, se fixe à la surface d’un support solide. L’étape suivante consiste donc à utiliser un solvant pour rincer cette surface. Le solvant décroche l’ADN et celui-ci finit dans une bouteille contenant un liquide spécial.
On se retrouve donc avec une bouteille « d’eau » contenant notre ADN. Maintenant, stocker des donnés c’est bien, mais faut-il encore pouvoir les lire. Mais là aussi les chercheurs ont trouvé une manière d’automatiser le processus. Premièrement, la machine ajoute un cocktail chimique dans la bouteille. Ce mélange a pour but de « préparer » l’ADN afin de le rendre lisible. Deuxièmement, une pompe transfert l’ADN et son liquide dans l’appareil de lecture. Finalement, l’appareil de lecture traduit cet ADN en données binaires et les transmet à l’ordinateur.
Et voilà tout marche ! Ou presque. En effet, il s’agit là d’une preuve de concept, la machine n’est pas sous sa forme définitive. La première amélioration que les chercheurs aimeraient apporter concerne le déplacement du liquide contenant l’ADN. Sous sa forme actuelle, la machine fonctionne avec une simple pompe et des petits flacons de verre. Ce que les scientifiques aimeraient faire, c’est tirer profit du projet Purple Drop.
Le Projet Purple Drop repose sur le fait que l’on peut dissoudre des ions (atomes chargés électriquement) dans l’eau. L’intérêt est qu’une fois chargée, l’eau peut être déplacée en générant des champs magnétiques via des courants électriques. L’équipe de Washington aimerait se servir de cette technologie pour mêler l’organique, que sont l’eau et l’ADN, à notre électronique actuelle, le tout, dans une seule machine.




Tout ceci semble bien beau sur le papier mais dans la réalité, ça donne quoi ? Eh bien c’est simple, il faut 21 heures pour encoder, stocker, puis décoder un mot de cinq lettres, le mot en question étant ici « hello » (ou 01001000 01000101 01001100 01001100 01001111 en binaire). La technologie n’est donc pas prête d’intégrer le marché. Malgré cela les scientifiques restent positifs et rappel que :
« Le but du projet n’était pas de montrer à quel point c’est rapide ou peu cher. L’objectif était simplement de prouver que l’automatisation du processus est possible »

L’ADN, c’est quoi et pourquoi est-ce une bonne solution pour le stockage de données ?
Ces scientifiques semblent satisfaits de leur percée technologique, mais on est en droit de se demander d’où vient le choix d’utiliser l’ADN. Commençons par les bases : l’ADN, ou acide désoxyribonucléique, est le support de l’information génétique de tous les organismes vivant de la planète. Il s’agit d’une très longue, mais néanmoins très simple, molécule en double hélice. Absolument toute l’information nécessaire au développement et au fonctionnement d’un être vivant s’y trouve.
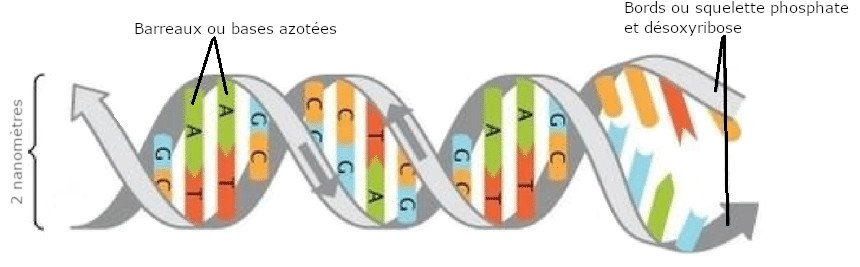

L’information est directement stockée dans la structure chimique de la molécule. En effet, la molécule est un assemblage. Les « bords » servent essentiellement au maintien de la forme tridimensionnelle, en revanche les « barreaux » sont le support de l’information. Chaque « barreau » est formé de deux moitiés qui sont reliées d’un côté aux « bords » et de l’autre côté à la moitié complémentaire du « barreaux ».
La complémentarité joue ici un rôle important. En effet, l’ADN n’est constitué que de quatre types de « demi-barreaux ». On les appelle les bases et chacune porte un nom : l’adénine la thymine la guanine et la cytosine que l’on abrège A, T, G et C. De par leur structure chimiques, elles ne peuvent s’apparier que d’une seule manière : A avec T et C avec G.
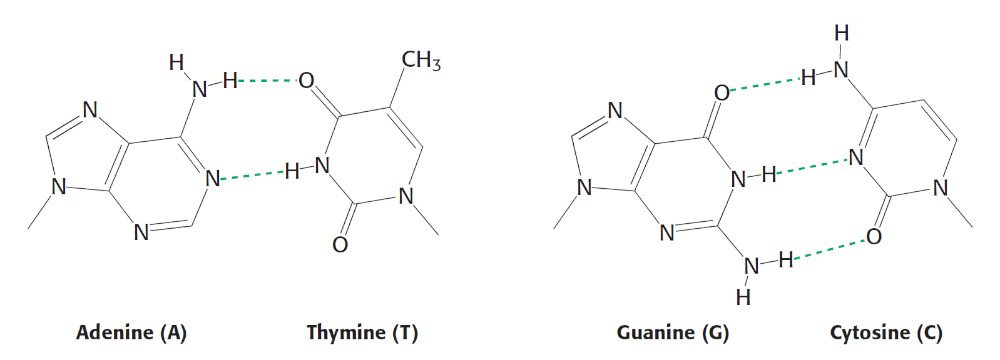

Comme les bases se lient par paire, dans notre cadre, on peut se contenter de considérer uniquement les paires de bases et non les bases individuellement. De ce fait, on a donc deux possibilités ; soit on a à faire à une paire AT, soit à une paire CG. Partant de là « il suffit » d’attribuer 1 à la paire AT et 0 à la paire CG et on a là traduit l’ADN en binaire.
On a donc une molécule hautement étudiée, que l’on sait synthétiser et modifier en laboratoire (notamment avec le CRISPR-Cas9). En plus de cela l’ADN est une molécule très stable (les bases sont doublement ou triplement liés les unes aux autres), ce qui la rend viable pour le stockage de longue durée. Finalement, l’ADN est une grande molécule à l’échelle de la cellule, mais à notre échelle est microscopique. On parle ici d’une molécule qui permet de stocker 215 pétabytes (1 024 térabyte) par gramme d’ADN !
Attendez-vous donc à réentendre parler d’ADN en informatique dans les prochaines années. Et qui sait, peut-être que d’ici quelques décennies, nous disposerons d’ordinateurs à « disques durs biologiques », stockant leur information dans des gouttelettes de liquide pleine d’ADN.






{kind=link}